Xin Chen
陈欣 | Senior Research Scientist
ByteDance | Silicon Valley
University of Chinese Academy of Sciences
I am a Senior Research Scientist and Tech Leader at ByteDance in Bay Area, USA, working on large-scale video generation, including Seedance. Previously, I was a Research Scientist T10 at Tencent working with Dr. Gang Yu. I received my Ph.D. from the Chinese Academy of Sciences under the supervision of Prof. Jingyi Yu, and was earlier supervised by Prof. Youyi Zheng at ShanghaiTech University.
My research interests focus on large-scale video generation, audio-visual foundation models, and unified multi-modal models. I have a great passion on new things and new ideas, my goal is to create Generative AI which is about humans, used for humans, and benefits humans.
Interests
- Large-scale Video Generation
- Multi-modal Generation
- Human Motion Generation
- Embodied Agents
- Computer Vision for Graphics
Services
-
[Conference Reviewer]
SIGGRAPH, CVPR, ICCV, ECCV, AAAI -
[Journal Reviewer]
TPAMI, TIP, IJCV, TMM
Collaborations
- Welcome discussions from academia and industry, especially regarding technology implementation and real-world impact. Feel free to reach out via email.
- I currently have internship positions available with the goal of conducting cutting-edge research in artificial intelligence. If you are interested, please send me an email.
News
- [2026/02] Seedance 2.0 is released 🎉
- [2026/02] ViBES and InterAgent accepted to CVPR 2026, congrats to Juze Zhang and Bin Li
- [2026/01] UniMAGE and FlowAct-R1, congrats to Jiaxu Zhang and Tianshu Hu
- [2026/01] Video-As-Prompt and MotionGPT3 accepted to ICLR 2026, congrats to Yuxuan Bian and Bingfan Zhu
- [2025/12] Seedance 1.5 Pro is released 🎉
- [2025/08] Motion2Motion accepted to SIGGRAPH Asia 2025, congrats to Ling-Hao Chen
- [2024/09] MeshXL and 3DET-Mamba accepted to NeurIPS 2024, congrats to Sijin Chen and Mingshen Li
- [2024/07] Joint ByteDance as a Research Scientist in San Jose, USA
- [2024/06] We introduce MeshXL, a 3D fundamental model for mesh generation
- [2024/04] Vote2Cap-DETR++ is accepted by T-PAMI 2024, congrats to Sijin Chen
- [2024/02] 3 papers accepted at CVPR 2024, congrats to Paint3D, LL3DA, OMG
- [2024/01] TapMo is accepted by ICLR 2024, congrats to Jiaxu Zhang
- [2023/12] We introduce Paint3D, a lighting-less texture diffusion model.
- [2023/12] We introduce AppAgent, a multimodal agent for smartphone apps.
- [2023/11] We introduce ShapeGPT, a multimodal LLM for 3D shape generation.
- [2023/11] We introduce LL3DA and M3DBench, a multimodal-language 3D assistant and benchmark.
- [2023/09] 3 papers accepted at NeurIPS 2023
- [2023/07] 1 paper accepted at ICCV 2023
- [2023/02] 2 papers accepted at CVPR 2023
- [2022/02] Join Tencent as a Research Scientist
- [2022/01] Receive my Ph.D. degree
- [2021/10] TightCap will be presented at ACM SIGGRAPH 2022
Publications
.js-id-selected




















Gallery
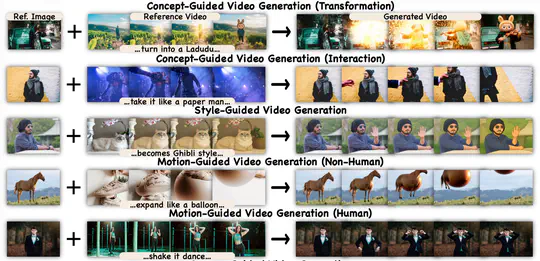
Seedance 2.0
Seedance 1.5
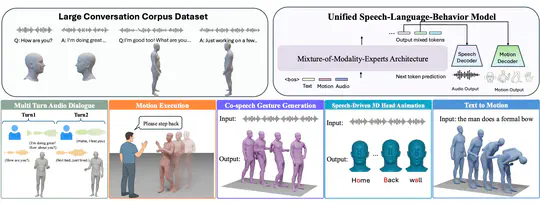
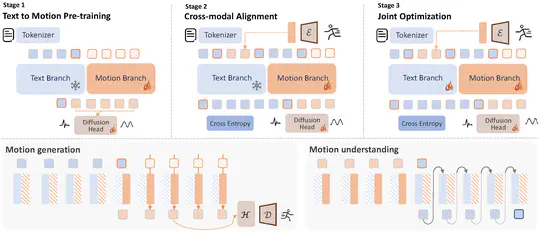
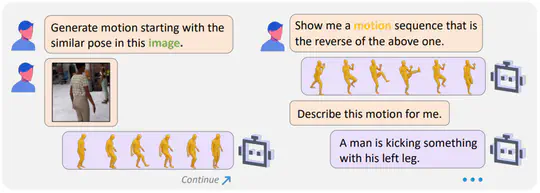
UniMAGE

Multi-view Static Dome System
Using more 92 6K cameras for static reconstruction
Using more 92 6K cameras for static reconstruction
Dynamic Performance Capture
Motion Capture

Multi-view Dynamic Dome System
Using more than 72 cameras for dynamic human reconstruction
Using more than 72 cameras for dynamic human reconstruction
Reconstructed 4D meshes
Reconstructed clothed human meshes
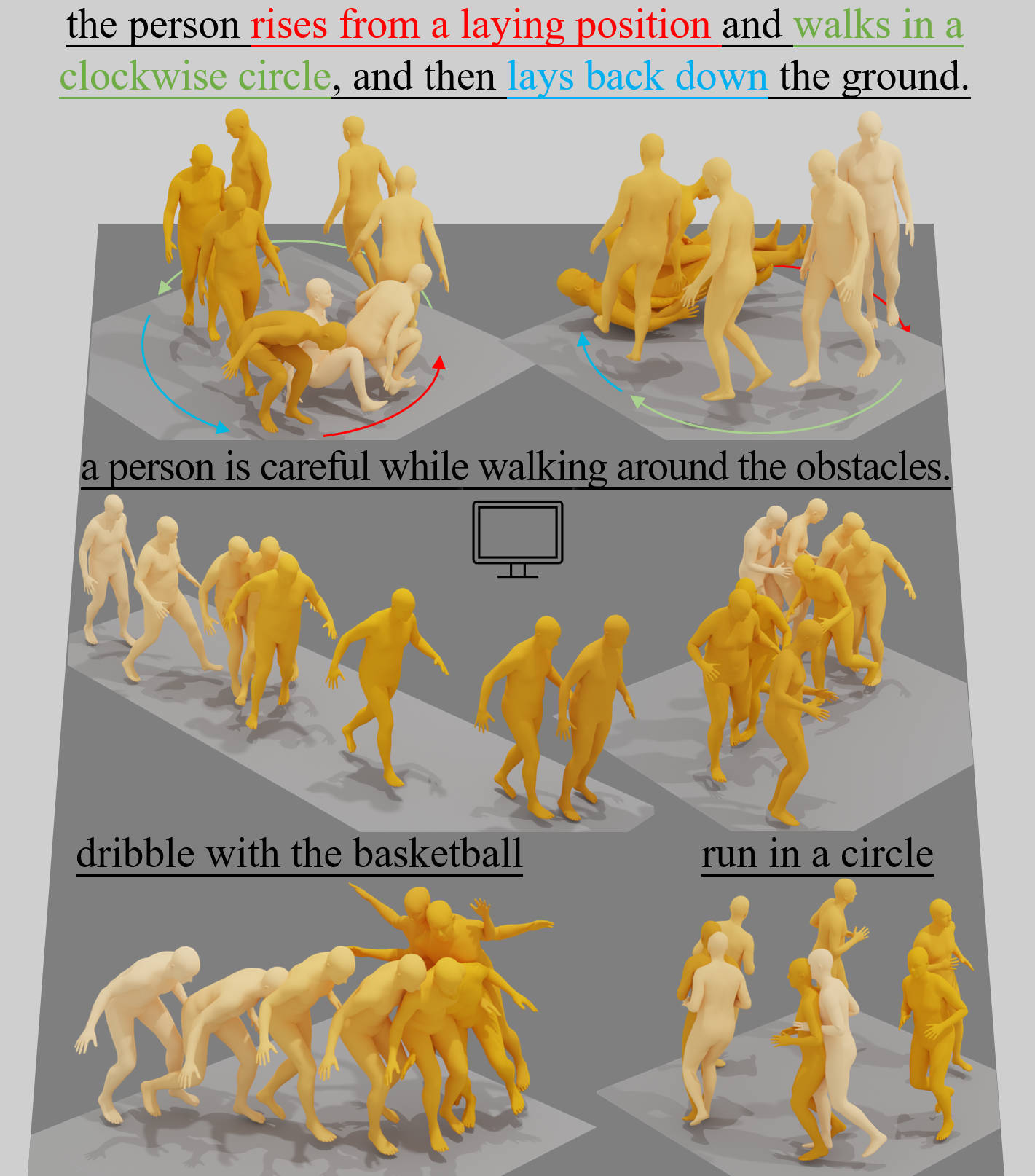
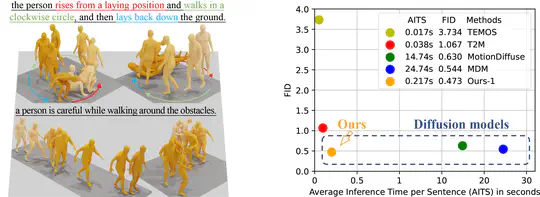
Motion-Latent-Diffusion
MotionGPT
Dynamic 4D Mesh Player
MeshXL
Paint3D

Invited Talks



Experiences
Senior Research Scientist
Senior Research Scientist focusing on large-scale video generation and multi-modal humanoid agents. Recognized as a 2025 Seed Spot Bonus Winner for outstanding contributions to Seedance 2.0.
Research Scientist
Research Scientist at QQ Image Lab, received two Outstanding performances and Tencent STAR Award 2023.
Research Scientist Intern
Research Scientist Intern at Tencent YouTuLab in 2020, focusing on the 3D human body reconstruction.
Research Engineer Intern
Research Engineer Intern at DGene Digital Technology Inc., my supervisor’s start-up, for world digitalization. I won the Best Outstanding Intern Award in 2018 for leading the mobile virtual fitting project.
Contact
- chris.chenxin.tech@gmail.com
- 1199 Coleman Ave | San Jose, Bay Area, USA
- DM Me